
70
visninger

Sidst opdateret den

Hvis du har brug for at analysere et datasæt, er Microsoft Excel det perfekte værktøj til jobbet. Mere specifikt gør drejetabeller til komplekse datasæt ting lettere.
Hvis du har brug for at analysere et datasæt, er Microsoft Excel det perfekte værktøj til jobbet. Du ved allerede, at Excel gemmer information i tabeller, men appens magt er inden for de værktøjer, du kan bruge til at udnytte de oplysninger, der er skjult i disse celler. Et af disse værktøjer er en pivottabel. Vi kiggede på funktionen tilbage i Excel 2010, og i Excel 2016 fortsætter vi med at se på, hvordan du kan bruge det til at manipulere og finde datatendenser.
Hvad er en pivottabel?
En pivottabel er et fint navn til sortering af oplysninger. Det er ideelt til beregning og opsummering af oplysninger, som du kan bruge til at opdele store tabeller til lige den rigtige mængde information, du har brug for. Du kan bruge Excel til at oprette en anbefalet pivottabel eller oprette en manuelt. Vi ser på begge.
En anbefalet pivottabel er introduceret i Excel 2013 og er et forudbestemt resume af dine data, som Excel anbefaler til dig. Du får muligvis ikke de oplysninger, du har brug for, afhængigt af dit datasæt, men til hurtig analyse kan det være praktisk. For at oprette en, skal du fremhæve datakilden (celleområdet i projektmappen, der indeholder de data, du vil analysere.) Vælg derefter fanen Indsæt og derefter Anbefalede pivottabeller.
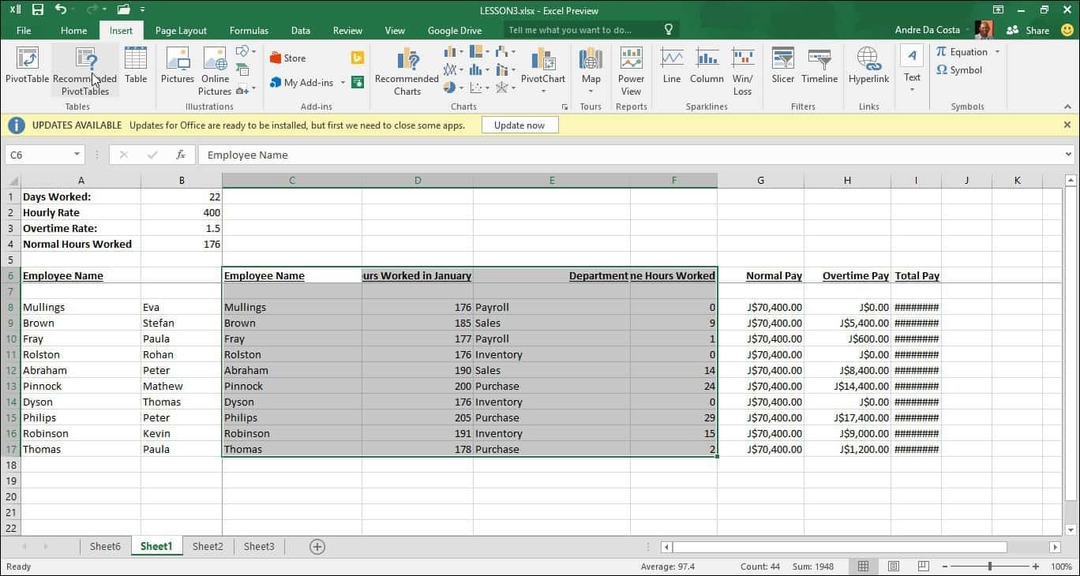
Når dialogboksen Vælg datakilde vises, skal du klikke på OK.
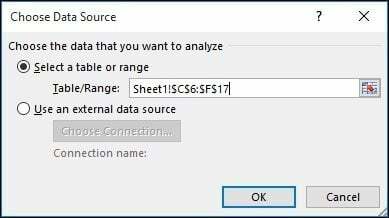
Et galleri med anbefalede PivotTable-stilarter vises, der giver forslag til, hvordan du måske ønsker at analysere de valgte data. I det følgende eksempel følger jeg antallet af medarbejdernavne efter arbejdstid i januar. Din vil variere afhængigt af den type data, du sorterer. Klik på OK.
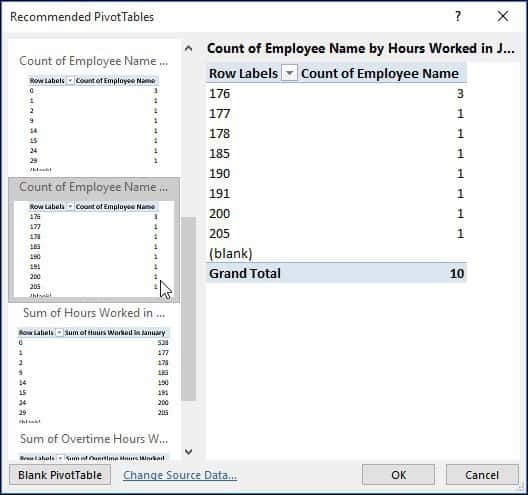
Som du kan se i nedenstående tabel, kan jeg få et indblik i, hvor mange personer, der arbejdede et vist antal timer i januar. Et scenarie som dette ville være dejligt at se, hvem der måske arbejder hårdest, arbejder overarbejde og fra hvilken afdeling inden for en virksomhed.
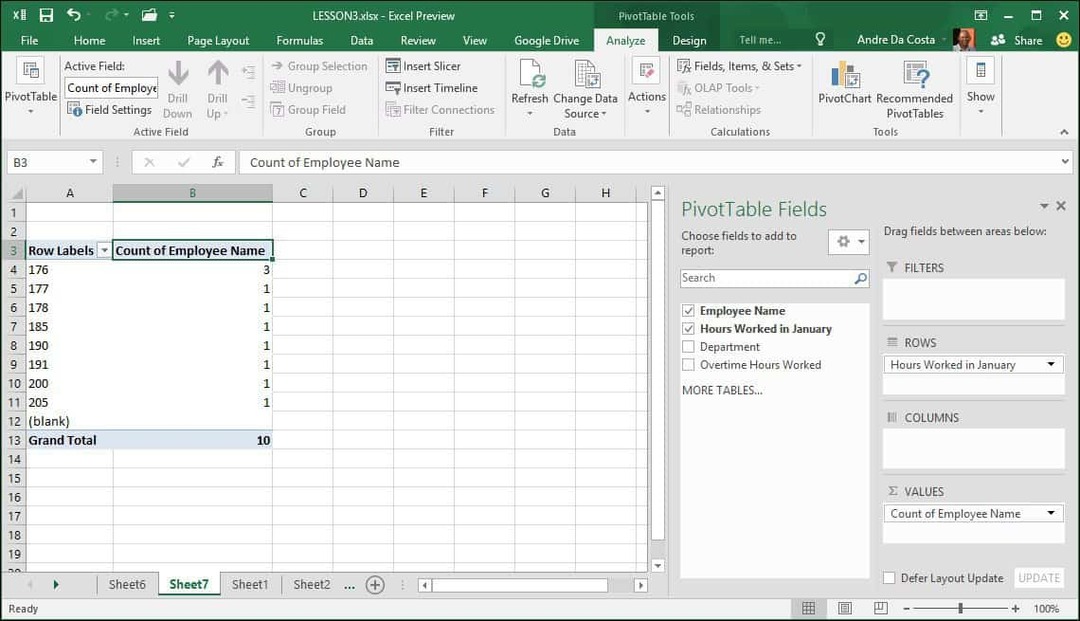
For at gøre det mere interessant, lad os grave dig nærmere ind og finde ud af, hvilken medarbejder der arbejder mest. Som du kan se, vises opgaveruden Pivot Table til højre og viser yderligere værktøjer, jeg kan bruge til at sortere og filtrere. For det følgende eksempel vil jeg tilføje Arbejdstid i januar til området Filtre og tilføj medarbejdernavnet til rækkeområdet. Når du har gjort det, vil du bemærke, at der er føjet et nyt felt til det kaldte ark Arbejdstid i januar.
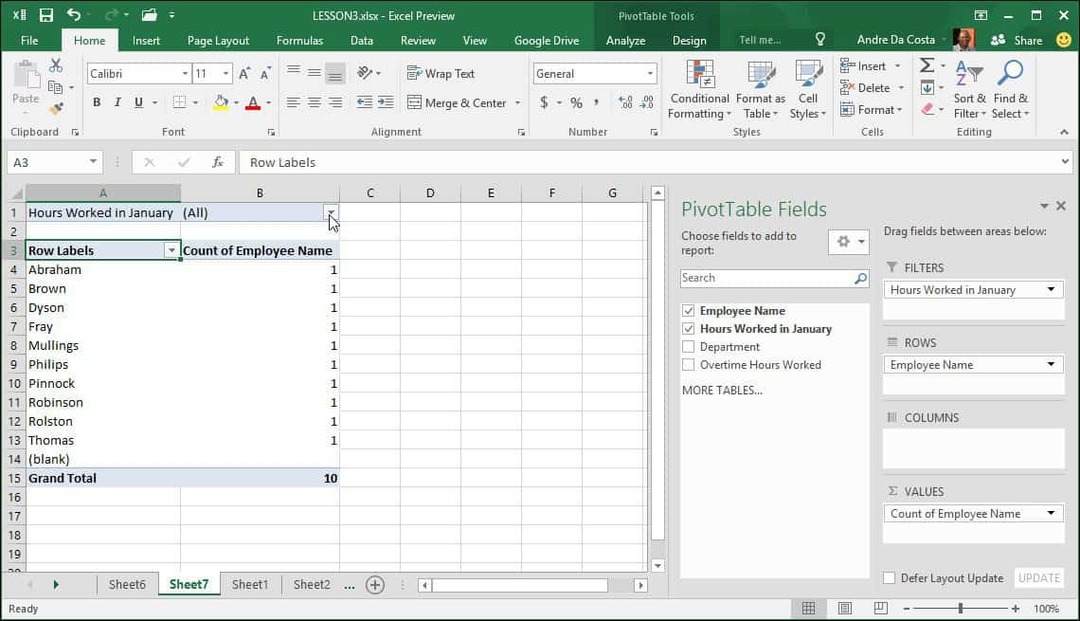
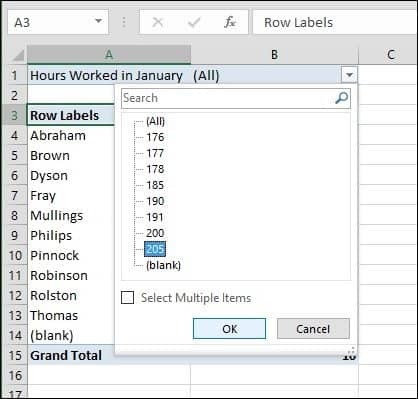
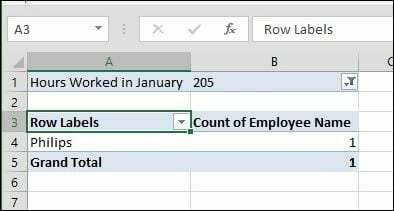
Når jeg klikker på filterboksen, kan jeg se det laveste og det højeste. Lad os vælge det højeste, der er 205, klik på OK. Så en medarbejder ved navn Philip arbejdede de fleste timer i januar. Det bliver ikke lettere end det.
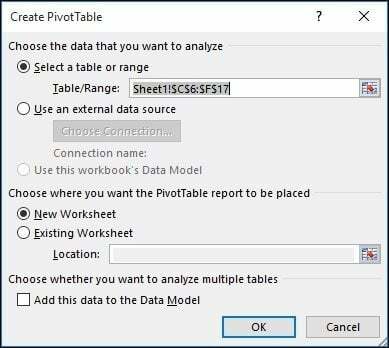
Hvis du vil have mere kontrol over, hvordan din pivottabel er designet, kan du gøre det selv ved hjælp af det almindelige pivottabelværktøj. Vælg igen datakilden eller det interval, hvor dataene er gemt i projektmappen, og vælg Indsæt> PivotTable.
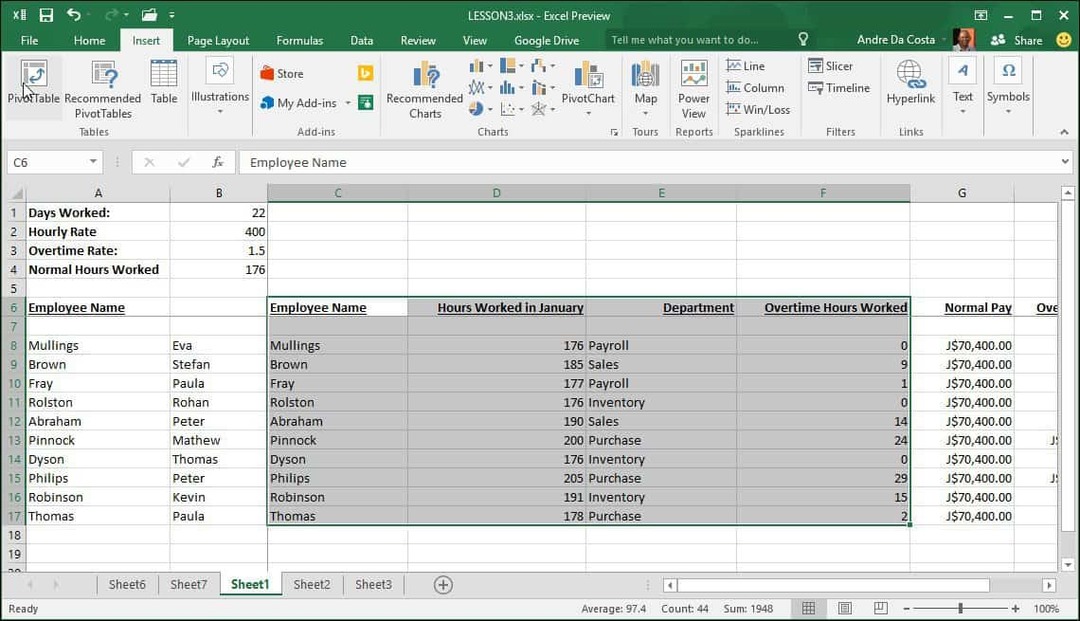
EN Opret PivotTable dialog vises med flere indstillinger. Da jeg arbejder med datakilden fra selve regnearket, forlader jeg standarden. Du kan vælge at tilføje pivottabellen til et eksisterende regneark eller et nyt. I dette tilfælde indsætter jeg det i et nyt ark.
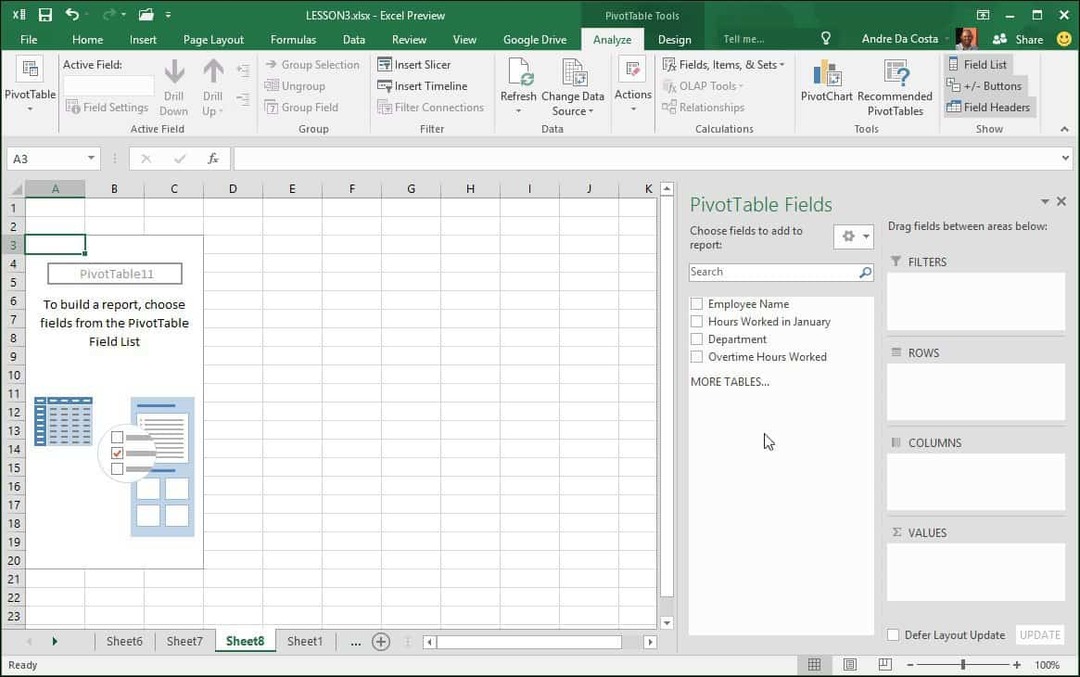
Du vil bemærke, at et nyt ark vises med forslag til, hvad du kan gøre. I dette særlige scenario vil jeg gerne vide, hvor mange timer der er arbejdet af medarbejdere i Salg. For at gøre det bruger jeg blot Afdeling til at filtrere listen ned og tilføje de andre tabeller til rækkerne, f.eks. Medarbejdernavnet og et antal arbejdstimer.
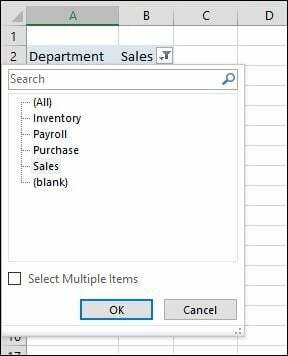
Klik på Afdelingsfilteret, og klik på Salg og derefter OK.
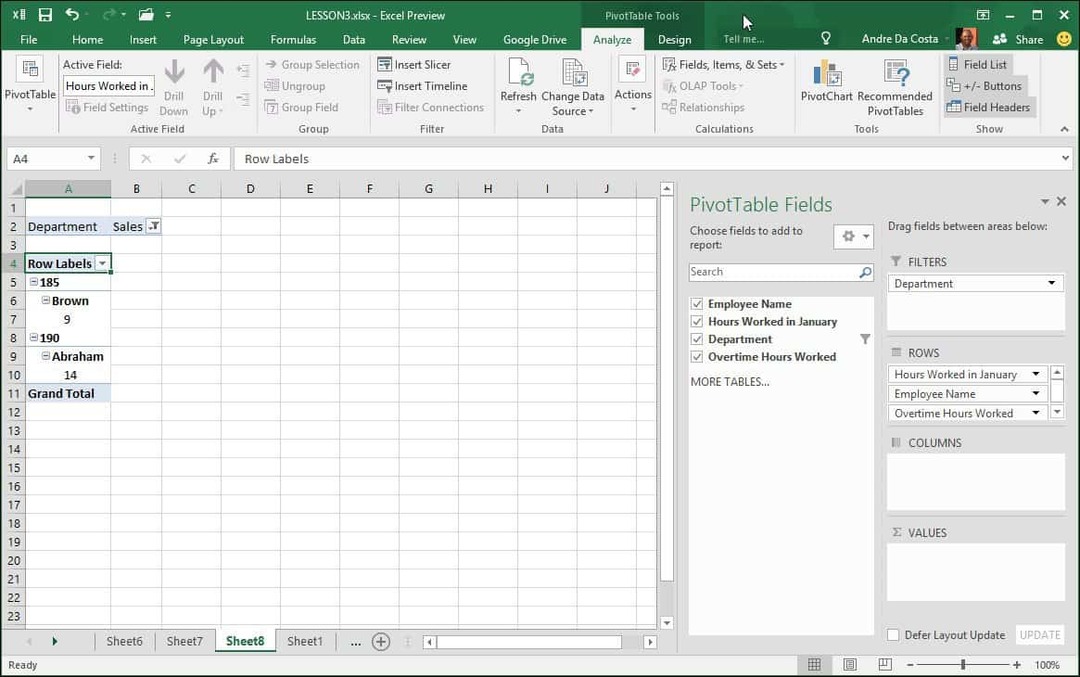
Umiddelbart kan jeg se, hvem der har arbejdet mest. Jeg tilføjede et ekstra felt til overarbejde bare for yderligere at analysere de leverede oplysninger.
Du skal nu have en god idé om, hvor kraftfulde drejetabeller er. Og hvordan de sparer tid ved at finde de nøjagtige oplysninger, du har brug for med lidt indsats. For en lille mængde data er dette muligvis overdreven. Men for større, mere komplekse datasæt, gør det dit job meget lettere.

