
124
visninger

Sidst opdateret den

En af de største fejl for nye webstedsejere er ikke at undersøge deres robots.txt-fil. Så hvad er det alligevel, og hvorfor så vigtigt? Vi har dine svar.
Hvis du ejer et websted og er interesseret i dit websteds SEO-helbred, skal du gøre dig meget fortrolig med robots.txt-filen på dit domæne. Tro det eller ej, det er et foruroligende stort antal mennesker, der hurtigt starter et domæne, installerer et hurtigt WordPress-websted og aldrig gider at gøre noget med deres robots.txt-fil.
Dette er farligt. En dårligt konfigureret robots.txt-fil kan faktisk ødelægge dit websteds SEO-helbred og ødelægge eventuelle chancer, du måtte have for at øge din trafik.
Det Robots.txt filen er passende navngivet, fordi det i det væsentlige er en fil, der viser direktiver for webroboterne (som søgemaskinrobotter) om, hvordan og hvad de kan gennemgå på dit websted. Dette har været en webstandard efterfulgt af websteder siden 1994, og alle større webcrawlere overholder standarden.
Filen gemmes i tekstformat (med en .txt-udvidelse) på rodmappen på dit websted. Faktisk kan du se ethvert websteds robot.txt-fil bare ved at skrive domænet efterfulgt af /robots.txt. Hvis du prøver dette med groovyPost, ser du et eksempel på en godt struktureret robot.txt-fil.
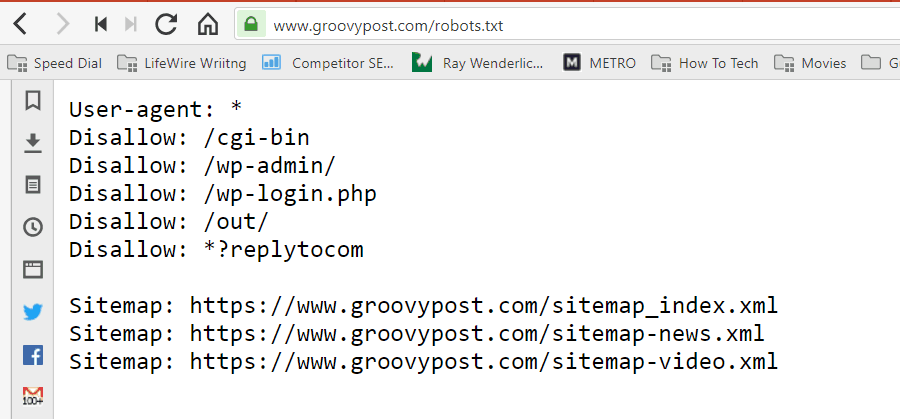
Filen er enkel, men effektiv. Denne eksempelfil adskiller ikke mellem robotter. Kommandoerne udstedes til alle robotter ved hjælp af Bruger-agent: * direktiv. Dette betyder, at alle kommandoer, der følger det, gælder for alle robotter, der besøger webstedet for at gennemgå det.
Du kan også specificere specifikke regler for specifikke webcrawlere. For eksempel kan du muligvis tillade Googlebot (Googles webcrawler) at gennemgå alle artikler på dit websted, men du ønsker måske at afvis den russiske webcrawler Yandex Bot fra at gennemgå artikler på dit websted, som har nedrørende oplysninger om Rusland.
Der er hundreder af webcrawlere, der søger internettet for information om websteder, men de 10 mest almindelige du skal være bekymrede over er listet her.
Ved at tage eksemplet ovenfor, hvis du vil tillade Googlebot at indeksere alt på dit websted, men ville blokerer Yandex for at indeksere dit russisk baserede artikelindhold, vil du tilføje følgende linjer til din robots.txt fil.
Bruger-agent: googlebot
Disallow: Disallow: / wp-admin /
Afvis: /wp-login.php
Bruger-agent: yandexbot
Disallow: Disallow: / wp-admin /
Afvis: /wp-login.php
Forlad: / russland /
Som du kan se, blokerer det første afsnit kun Google fra at gennemgå din WordPress-login-side og administrative sider. Det andet afsnit blokerer Yandex for det samme, men også for hele området på dit websted, hvor du har offentliggjort artikler med anti-Rusland-indhold.
Dette er et simpelt eksempel på, hvordan du kan bruge Disallow kommando til at kontrollere specifikke webcrawlere, der besøger dit websted.
Disallow er ikke den eneste kommando, du har adgang til i din robots.txt-fil. Du kan også bruge en hvilken som helst af de andre kommandoer, der styrer, hvordan en robot kan gennemgå dit websted.
Husk, at bots vil gøre det kun lyt til de kommandoer, du har leveret, når du specificerer navnet på bot.
En almindelig fejl, som folk begår, er at afvise områder som / wp-admin / fra alle bots, men angiv derefter et googlebot-afsnit og kun at afvise andre områder (som / om /).
Da bots kun følger de kommandoer, du angiver i deres afsnit, skal du ændre alle disse andre kommandoer, som du har angivet for alle bots (ved hjælp af * brugeragenten).
Husk, at robots.txt er beregnet til at hjælpe legitime bots (som søgemaskinebots) gennemgå dit websted mere effektivt.
Der er masser af ubehagelige gennemsøgere derude, der gennemsøger dit websted for at gøre ting som at skrabe e-mail-adresser eller stjæle dit indhold. Hvis du vil prøve at bruge din robots.txt-fil til at blokere disse crawler fra at gennemgå noget på dit websted, skal du ikke gider. Oprettelsen af disse crawlere ignorerer typisk alt, hvad du har lagt i din robots.txt-fil.
At få Googles søgemaskine til at gennemgå så meget kvalitetsindhold på dit websted som muligt er en primær bekymring for de fleste webstedsejere.
Google udvider dog kun et begrænset gennemsøgningsbudget og gennemsøgningshastighed på individuelle websteder. Gennemsøgningsfrekvensen er, hvor mange anmodninger pr. Sekund Googlebot fremsætter til dit websted under gennemsøgningsbegivenheden.
Mere vigtigt er gennemsøgningsbudgettet, hvilket er hvor mange samlede anmodninger Googlebot vil anmode om at gennemgå dit websted i en session. Google "bruger" sit gennemsøgningsbudget ved at fokusere på områder på dit websted, der er meget populære eller har ændret sig for nylig.
Du er ikke blind for disse oplysninger. Hvis du besøger Googles webmasterværktøjer, kan du se, hvordan webcrawleren håndterer dit websted.
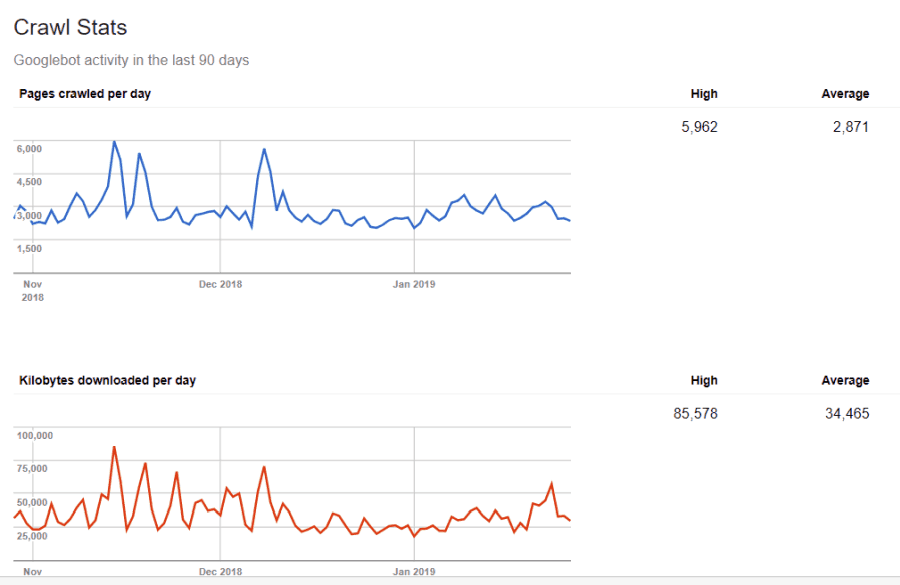
Som du kan se, holder crawlen sin aktivitet på dit websted temmelig konstant hver dag. Det gennemsøger ikke alle websteder, men kun de, det anser for at være de vigtigste.
Hvorfor overlade det til Googlebot at beslutte, hvad der er vigtigt på dit websted, når du kan bruge din robots.txt-fil til at fortælle det, hvad de vigtigste sider er? Dette forhindrer Googlebot i at spilde tid på sider med lav værdi på dit websted.
Med Google Webmasterværktøjer kan du også kontrollere, om Googlebot læser din robots.txt-fil fint, og om der er fejl.
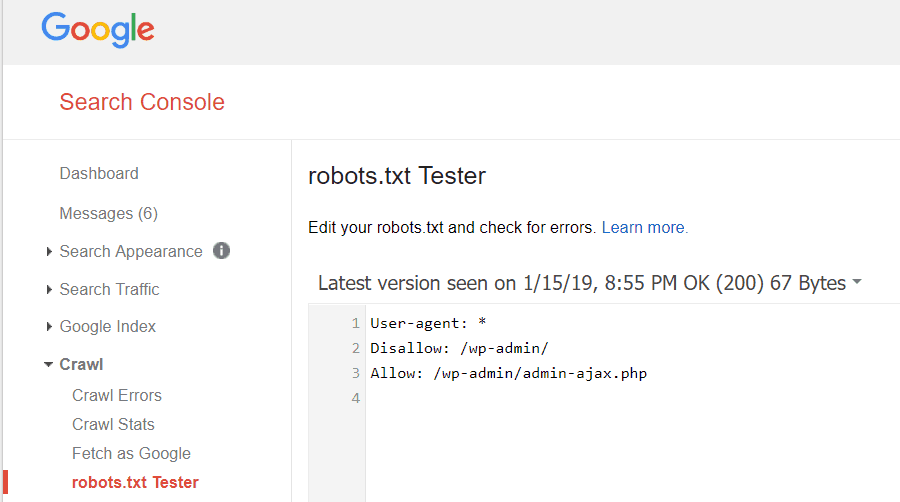
Dette hjælper dig med at bekræfte, at du har struktureret din robots.txt-fil korrekt.
Hvilke sider skal du afvise fra Googlebot? Det er godt for dit websteds SEO at afvise følgende kategorier af sider.
Den største fejl, som nye webstedsejere begår, er aldrig engang at se på deres robots.txt-fil. Den værste situation kan være, at robots.txt-filen faktisk blokerer dit websted eller områder på dit websted fra at blive gennemsøgt overhovedet.
Sørg for at gennemgå din robots.txt-fil, og sørg for, at den er optimeret. På denne måde "se" Google og andre vigtige søgemaskiner alle de fantastiske ting, du tilbyder verden med dit websted.
